Welcome to MOE’s documentation!¶
Contents:
What is MOE?¶
MOE (Metric Optimization Engine) is an efficient way to optimize a system’s parameters, when evaluating parameters is time-consuming or expensive.
Here are some examples of when you could use MOE:
- Optimizing a system’s click-through rate (CTR). MOE is useful when evaluating CTR requires running an A/B test on real user traffic, and getting statistically significant results requires running this test for a substantial amount of time (hours, days, or even weeks).
- Optimizing tunable parameters of a machine-learning prediction method. MOE is useful if calculating the prediction error for one choice of the parameters takes a long time, which might happen because the prediction method is complex and takes a long time to train, or because the data used to evaluate the error is huge.
- Optimizing the design of an engineering system (an airplane, the traffic network in a city, a combustion engine, a hospital). MOE is useful if evaluating a design requires running a complex physics-based numerical simulation on a supercomputer.
- Optimizing the parameters of a real-world experiment (a chemistry, biology, or physics experiment, a drug trial). MOE is useful when every experiment needs to be physically created in a lab, or very few experiments can be run in parallel.
MOE is ideal for problems in which the optimization problem’s objective function is a black box, not necessarily convex or concave, derivatives are unavailable, and we seek a global optimum, rather than just a local one. This ability to handle black-box objective functions allows us to use MOE to optimize nearly any system, without requiring any internal knowledge or access. To use MOE, we simply need to specify some objective function, some set of parameters, and any historical data we may have from previous evaluations of the objective function. MOE then finds the set of parameters that maximize (or minimize) the objective function, while evaluating the objective function as little as possible.
Inside, MOE uses Bayesian global optimization, which performs optimization using Bayesian statistics and optimal learning.
Optimal learning is the study of efficient methods for collecting information, particularly when doing so is time-consuming or expensive, and was developed and popularized from its roots in decision theory by Prof. Peter Frazier (Cornell, Operations Research and Information Engineering) and Prof. Warren Powell (Princeton, Operations Research and Financial Engineering). For more information about the mathematics of optimal learning, and more real-world applications like heart surgery, drug discovery, and materials science, see these intro slides to optimal learning.
Example:
To illustrate how MOE works, suppose we wish to maximize the click-through-rate (CTR) on a website we manage, by varying some real-valued parameter vector \(\vec{x}\) that governs how site content is presented to the user. Evaluating the CTR for a new set of parameters requires running an A/B test over a period of several days. We write this problem mathematically as,
We want to find the best set of parameters \(\vec{x}\) while evaluating the underlying function (CTR) as few times as possible. See Objective Functions for more examples of objective functions and the best ways to combine metrics.
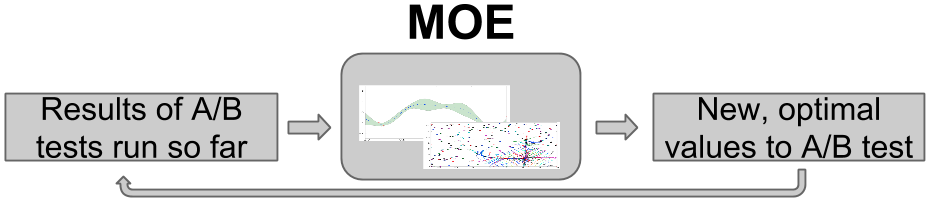
MOE builds the following loop, in which it takes the results from those A/B tests that have been run so far, processes them through its internal engine, and then determines at which parameter vector \(\vec{x}\) it would be most valuable to next observe the CTR. MOE runs an A/B test at this new parameter vector, and then repeats the loop.
This choice of the most valuable point trades a desire to evaluate points where we have a lot of uncertainty about the CTR (this is called exploration), and to evaluate points where we think the CTR is large (this is called exploitation).
By continuing to optimize over many iterations, MOE quickly finds approximate optima, or points with large CTR. As the world changes over time, MOE can surf these shifting optima as they move, staying at the peak of the potentially changing objective function in parameter space as time advances.
For more examples on how MOE can be used see Examples
Video and slidedeck introduction to MOE:
MOE does this internally by:
Building a Gaussian Process (GP) with the historical data
Optimizing the hyperparameters of the Gaussian Process (model selection)
Finding the point(s) of highest Expected Improvement (EI)
Returning the points to sample, then repeat
Externally you can use MOE through:
- The REST interface
- The Python interface
- The C++ interface
- The CUDA kernels.
You can be up and optimizing in a matter of minutes.
Quick Install¶
Install in docker:¶
This is the recommended way to run the MOE REST server. All dependencies and building is done automatically and in an isolated container.
Docker (http://docs.docker.io/) is a container based virtualization framework. Unlike traditional virtualization Docker is fast, lightweight and easy to use. Docker allows you to create containers holding all the dependencies for an application. Each container is kept isolated from any other, and nothing gets shared.
$ docker pull yelpmoe/latest # You can also pull specific versions like yelpmoe/v0.1.0
$ docker run -p 6543:6543 yelpmoe/latest
If you are on OSX, or want a build based on the current master branch you may need to build this manually.
$ git clone https://github.com/Yelp/MOE.git
$ cd MOE
$ docker build -t moe_container .
$ docker run -p 6543:6543 moe_container
The webserver and REST interface is now running on port 6543 from within the container. http://localhost:6543
Build from source (linux and OSX 10.8 and 10.9 supported)¶
Quick Start¶
REST/web server and interactive demo¶
To get the REST server running locally, from the directory MOE is installed:
$ pserve --reload development.ini # MOE server is now running at http://localhost:6543
You can access the server from a browser or from the command line,
$ curl -X POST -H "Content-Type: application/json" -d '{"domain_info": {"dim": 1}, "points_to_evaluate": [[0.1], [0.5], [0.9]], "gp_historical_info": {"points_sampled": [{"value_var": 0.01, "value": 0.1, "point": [0.0]}, {"value_var": 0.01, "value": 0.2, "point": [1.0]}]}}' http://127.0.0.1:6543/gp/ei
gp_ei endpoint documentation: moe.views.rest.gp_ei
From ipython¶
$ ipython
> from moe.easy_interface.experiment import Experiment
> from moe.easy_interface.simple_endpoint import gp_next_points
> exp = Experiment([[0, 2], [0, 4]])
> exp.historical_data.append_sample_points([[[0, 0], 1.0, 0.01]])
> next_point_to_sample = gp_next_points(exp)
> print next_point_to_sample
easy_interface documentation: moe.easy_interface package
Within Python¶
See moe_examples.next_point_via_simple_endpoint or Examples for more examples.
import math
import random
from moe.easy_interface.experiment import Experiment
from moe.easy_interface.simple_endpoint import gp_next_points
from moe.optimal_learning.python.data_containers import SamplePoint
# Note: this function can be anything, the output of a batch, results of an A/B experiment, the value of a physical experiment etc.
def function_to_minimize(x):
"""Calculate an aribitrary 2-d function with some noise with minimum near [1, 2.6]."""
return math.sin(x[0]) * math.cos(x[1]) + math.cos(x[0] + x[1]) + random.uniform(-0.02, 0.02)
if __name__ == '__main__':
exp = Experiment([[0, 2], [0, 4]]) # 2D experiment, we build a tensor product domain
# Bootstrap with some known or already sampled point(s)
exp.historical_data.append_sample_points([
SamplePoint([0, 0], function_to_minimize([0, 0]), 0.05), # Iterables of the form [point, f_val, f_var] are also allowed
])
# Sample 20 points
for i in range(20):
# Use MOE to determine what is the point with highest Expected Improvement to use next
next_point_to_sample = gp_next_points(exp)[0] # By default we only ask for one point
# Sample the point from our objective function, we can replace this with any function
value_of_next_point = function_to_minimize(next_point_to_sample)
print "Sampled f({0:s}) = {1:.18E}".format(str(next_point_to_sample), value_of_next_point)
# Add the information about the point to the experiment historical data to inform the GP
exp.historical_data.append_sample_points([SamplePoint(next_point_to_sample, value_of_next_point, 0.01)]) # We can add some noise
Licence¶
MOE is licensed under the Apache License, Version 2.0
Source Documentation¶
Documentation¶
- Why Do We Need MOE?
- Install
- How does MOE work?
- Demo Tutorial
- Pretty Endpoints
- Objective Functions
- Multi-Armed Bandits
- Examples
- Contributing
- Frequently Asked Questions
- What license is MOE released under?
- When should I use MOE?
- What is the time complexity of MOE?
- How do I cite MOE?
- Why does MOE take so long to return the next points to sample for some inputs?
- How do I bootstrap MOE? What initial data does it need?
- How many function evaluations do I need before MOE is “done”?
- How many function evaluations do I perform before I update the hyperparameters of the GP?
- Will you accept my pull request?
Python Files¶
- moe package
- Subpackages
- moe.bandit package
- moe.build package
- moe.easy_interface package
- moe.optimal_learning package
- moe.tests package
- moe.views package
- Subpackages
- Submodules
- moe.views.bandit_pretty_view module
- moe.views.constant module
- moe.views.exceptions module
- moe.views.frontend module
- moe.views.gp_hyperparameter_update module
- moe.views.gp_next_points_pretty_view module
- moe.views.gp_pretty_view module
- moe.views.optimizable_gp_pretty_view module
- moe.views.pretty_view module
- moe.views.utils module
- Module contents
- Submodules
- moe.resources module
- Module contents
- Subpackages
- moe_examples package
- Subpackages
- moe_examples.tests package
- Submodules
- moe_examples.tests.bandit_example_test module
- moe_examples.tests.combined_example_test module
- moe_examples.tests.hyper_opt_of_gp_from_historical_data_test module
- moe_examples.tests.mean_and_var_of_gp_from_historic_data_test module
- moe_examples.tests.moe_example_test_case module
- moe_examples.tests.next_point_via_simple_endpoint_test module
- Module contents
- moe_examples.tests package
- Submodules
- moe_examples.bandit_example module
- moe_examples.blog_post_example_ab_testing module
- moe_examples.combined_example module
- moe_examples.hyper_opt_of_gp_from_historical_data module
- moe_examples.mean_and_var_of_gp_from_historic_data module
- moe_examples.next_point_via_simple_endpoint module
- Module contents
- Subpackages
C++ Files¶
- C++ Files
- gpp_optimization_test
- gpp_domain_test
- gpp_expected_improvement_gpu
- gpp_heuristic_expected_improvement_optimization_test
- gpp_linear_algebra_test
- gpp_geometry
- gpp_heuristic_expected_improvement_optimization
- gpp_linear_algebra-inl
- gpp_test_utils
- gpp_logging
- gpp_covariance
- gpp_python_test
- gpp_domain
- gpp_python_common
- gpp_hyperparameter_optimization_demo
- gpp_geometry_test
- gpp_math_test
- gpp_cuda_math
- gpp_python_model_selection
- gpp_math
- gpp_random_test
- gpp_optimizer_parameters
- gpp_expected_improvement_demo
- gpp_optimization
- gpp_test_utils_test
- gpp_linear_algebra
- gpp_python_expected_improvement
- gpp_exception
- gpp_model_selection
- gpp_random
- gpp_covariance_test
- gpp_mock_optimization_objective_functions
- gpp_python
- gpp_model_selection_test
- gpp_hyper_and_EI_demo
- gpp_python_gaussian_process
- gpp_common
- gpp_expected_improvement_gpu_test